Reusable Elixir Libraries
February 8, 2020
One of my new goals is to try to make my elixir libraries more reusable. It’s an easy mark to hit if you only use modules and functions. But once you start adding processes, ETS tables, and other stateful constructs, the solutions get murky.
I thought it would be good to write out my thoughts and explain some of the patterns that I’ve been using. There are probably other, better solutions. But these are the ones that I use. I’m going to use the term “library” throughout this post, but none of these techniques are limited to libraries in the traditional sense. I use all of these methods when building components or subsystems at work.
OTP Applications
This solution is the easiest but also the most limiting. If you only provide an OTP application, then your users don’t have to worry about configuring anything, and the API is typically more straightforward. But OTP Apps are singletons. Configuration becomes much more complicated, the user has limited control, and you risk colliding with other libraries who are also dependent on your app. But an OTP app’s most significant drawbacks are also its biggest strengths. There might not be any need for the user to provide configuration. Maybe the supervision strategy is complex, and it would be error-prone to ask the user to manage it themselves. You need to look at your objectives and decide the best approach.
Anecdotally, the majority of times that I’ve built a library that only provided an OTP app, I’ve ended up changing it. But that probably says more about me than it says anything about OTP apps.
Starting with a single process
My typical approach is to provide processes that the user can start in their supervision tree. This pattern takes more work, but it isolates the component from the rest of the system and gives more control to the user of the library.
To make this concrete, we can look at an example. Let’s say that we want to provide a small cache that users can include in their supervision tree. A naive implementation might look like this:
defmodule Cache do
use GenServer
def child_spec(opts) do
%{
id: opts[:name] || __MODULE__,
start: {__MODULE__, :start_link, [opts]},
}
end
def start_link(opts) do
server_opts = Keyword.take(opts, [:name])
GenServer.start_link(__MODULE__, opts, server_opts)
end
def get(server, key) do
GenServer.call(server, {:get, key})
end
def put(server, key, value) do
GenServer.call(server, {:put, key, value})
end
def init(opts) do
{:ok, %{kvs: %{}, opts: opts}}
end
def handle_call({:get, key}, _from, data) do
{:reply, data.kvs[key], data}
end
def handle_call({:put, key, val}, _from, data) do
{:reply, :ok, put_in(data, [:kvs, key], val)}
end
end
That’s it! That’s the entire trick. We simply rely on the name registration rules that other OTP processes use. Our users are now free to start a cache however they want.
# Access with pid
{:ok, pid} = Cache.start_link([])
Cache.put(pid, :foo, "foo")
123 = Cache.get(pid, :foo)
# Start a process with a name.
Cache.start_link([name: MyCache])
Cache.put(MyCache, :foo, "foo")
123 = Cache.get(MyCache, :foo)
Unit testing is simple and isolated.
defmodule CacheTest do
use ExUnit.Case, async: true
setup do
{:ok, cache} = Cache.start_link([])
{:ok, cache: cache}
end
test "it stores values", %{cache: cache} do
assert Cache.get(cache, :key) == nil
assert Cache.put(cache, :key, "value") == :ok
assert Cache.get(cache, :key) == "value"
end
end
And if the user wants to start multiple instances of the cache, they’re free to do so.
defmodule CacheExample.Application do
@moduledoc false
use Application
def start(_type, _args) do
children = [
{Cache, name: PrimaryCache, ttl: 500},
{Cache, name: BackupCache, ttl: 5_000},
]
opts = [strategy: :one_for_one, name: CacheExample.Supervisor]
Supervisor.start_link(children, opts)
end
end
Providing a supervision tree
This strategy is obvious when you only need to provide a single process. But if you need to provide a set of processes with a supervisor, then things get more complicated.
For instance, if we wanted to provide a more robust cache, then we’d want to use an ETS table. We could start the ETS table inside of our cache process, but if the cache process crashes, we’ll also lose the ETS table. A better approach would be to start both the ETS table and the writing process underneath a supervisor like so.
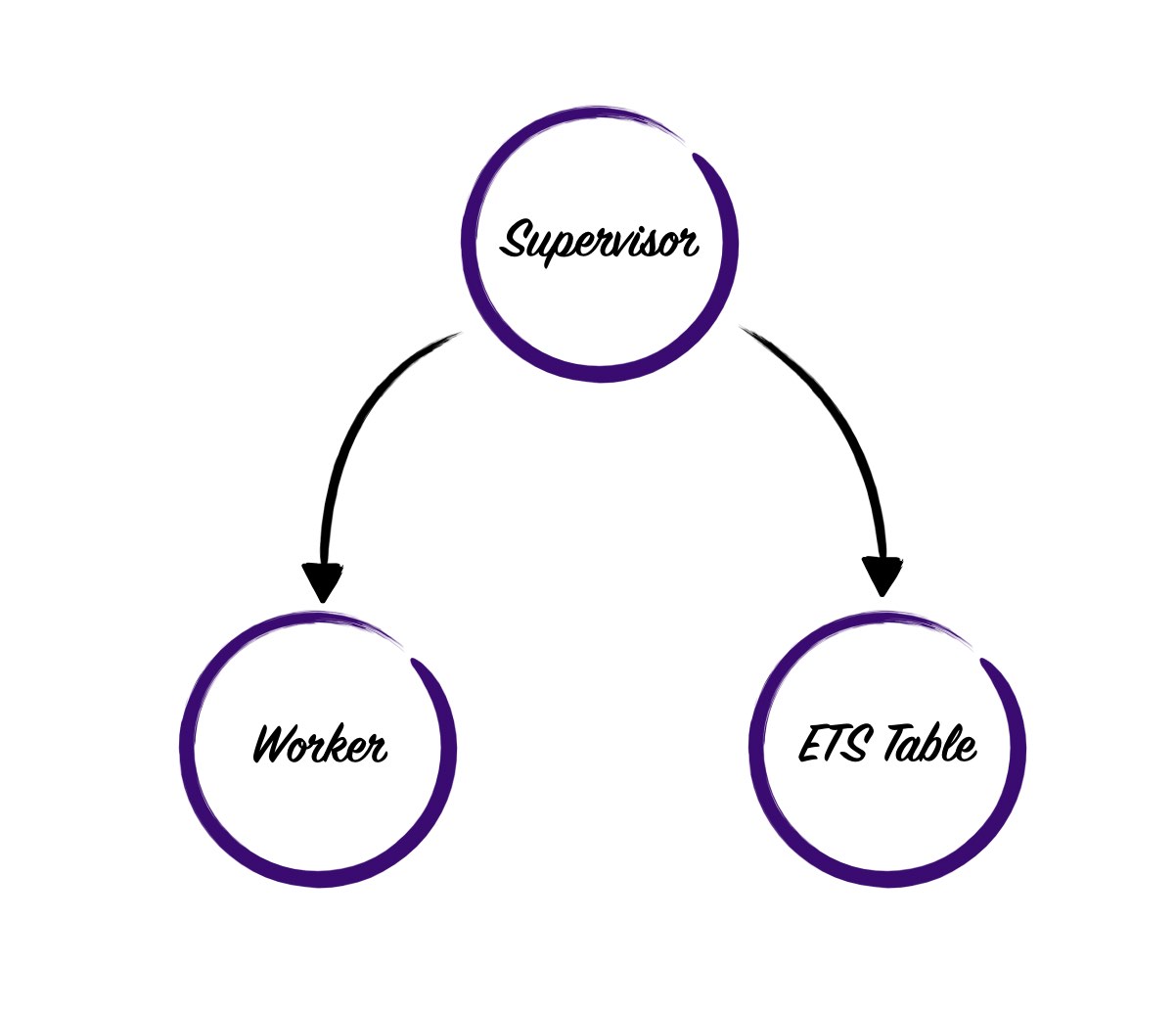
The problem with this approach is that its difficult for the supervisor’s children to identify and communicate with one another. There are some smart ways we could solve the problem, but my preference is to do something dumb and easy.
We’re going to require that users pass in a :name when they start a cache. We’ll then used the passed in name to derive names for the supervisors children. By naming all of the processes in this way the siblings will all be able to find each other. This requirement reduces our flexibility, but in my experience, it’s a reasonable tradeoff to make.
We’ll start by converting our API to a supervisor.
defmodule Cache do
use Supervisor
def child_spec(opts) do
%{
id: (opts[:name] || raise ArgumentError, "Cache name is required"),
start: {__MODULE__, :start_link, [opts]},
}
end
def start_link(opts) do
name = opts[:name] || raise ArgumentError, "Cache name is required"
Supervisor.start_link(__MODULE__, opts, name: name)
end
def get(name, key) do
Cache.Storage.get(storage_name(name), key)
end
def put(name, key, val) do
Cache.Storage.put(storage_name(name), key, val)
end
def init(opts) do
name = opts[:name]
table = :ets.new(storage_name(name), [:named_table, :public, :set])
children = [
{Cache.Storage, [name: storage_name(name)]},
]
Supervisor.init(children, strategy: :one_for_one)
end
defp storage_name(name) do
:"#{name}.Storage"
end
end
The supervisor ensures that the user has provided a name; if they haven’t, it raises an error. It then creates an ETS table and starts a Storage process as a worker. Both the Storage worker and the ETS table are given the same name. This symmetry reduces complexity in the storage worker and keeps all of the naming logic inside the supervisor.
We can move all of our old Cache logic into the Storage module and make a few tweaks.
defmodule Cache.Storage do
@moduledoc false
use GenServer
def child_spec(opts) do
%{
id: opts[:name],
start: {__MODULE__, :start_link, [opts]},
}
end
def start_link(opts) do
GenServer.start_link(__MODULE__, opts, name: opts[:name])
end
def get(server, key) do
case :ets.lookup(server, key) do
[{^key, value}] ->
value
[] ->
nil
end
end
def put(server, key, value) do
GenServer.call(server, {:put, key, value})
end
def init(opts) do
{:ok, %{table: opts[:name]}}
end
def handle_call({:put, key, val}, _from, data) do
true = :ets.insert(data.table, {key, val})
{:reply, :ok, data}
end
end
These changes aren’t too dramatic. All “gets” go directly to the ETS table and “puts” go to the storage process. It may seem awkward to split reads and writes this way. In some cases, it might make more sense to have the client send writes and reads directly to ETS and skip the process. Or invert the logic and have everything go through a process. I use the split approach for read heavy workloads because it makes it easier to implement logic like key eviction or CAS operations.
With those changes done, we’ve successfully isolated our errors. If the storage process crashes, we won’t lose the values in our ETS table.
iex(4)> Cache.put(PrimaryCache, :foo, "bar")
:ok
iex(5)> Cache.get(PrimaryCache, :foo)
"bar"
iex(7)> Process.whereis(PrimaryCache.Storage) |> Process.exit(:brutal_kill)
true
iex(8)> Cache.get(PrimaryCache, :foo)
"bar"
This pattern also makes it simple to extend the system in the future. For instance, if we wanted to create a process to clean up old keys, we could add it to our existing supervision tree and name it correctly.
def init(opts) do
name = opts[:name]
table = :ets.new(storage_name(name), [:named_table, :public, :set])
children = [
{Cache.Storage, [name: storage_name(name)]},
{Cache.Cleaner, [name: cleaner_name(name), table: table, ttl: opts[:ttl]]},
]
Supervisor.init(children, strategy: :one_for_one)
end
defp storage_name(name) do
:"#{name}.Storage"
end
defp cleaner_name(name) do
:"#{name}.Cleaner"
end
At this point, we’ve built a stateful library that is re-usable in multiple contexts. Users can choose to configure it and supervise it whichever way they feel best. I would usually stop here. But there’s one more step we can take to make our API more pleasant to use.
Improving the user experience
Every time a user calls our cache, they have to pass the name of the cache as the first argument, which can quickly become tedious. A lot of people find PrimaryCache.get(:foo) more appealing than Cache.get(PrimaryCache, :foo) and who am I to tell them they’re wrong.
Fortunately, our design makes this easy to add. We just need a little help from our venerable friend, the __using__ macro.
defmodule Cache do
defmacro __using__(_opts) do
quote do
def child_spec(opts) do
opts = Keyword.put_new(opts, :name, __MODULE__)
Cache.child_spec(opts)
end
def start_link(opts) do
opts = Keyword.put_new(opts, :name, __MODULE__)
Cache.start_link(opts)
end
def get(key), do: Cache.get(__MODULE__, key)
def put(key, value), do: Cache.put(__MODULE__, key, value)
end
end
# The functions we already wrote...
end
The macro defines some default functions that start and access a cache based on the name of the module. The user can then add their cache module to their tree similar to before.
defmodule CacheExample.PrimaryCache do
use Cache
end
defmodule CacheExample.Application do
def start(_type, _args) do
children = [
{CacheExample.PrimaryCache, ttl: 500},
]
opts = [strategy: :one_for_one, name: CacheExample.Supervisor]
Supervisor.start_link(children, opts)
end
end
Conclusion
I hope that this has given you some ideas about how to build more reusable, stateful libraries. There are tons more out there, all with different tradeoffs. But most of the time, these simple approaches are all you need. Regardless of which solution you choose, I hope this demonstrates that you can provide a friendly API, which gives users more control and doesn’t give up isolation. If you follow these patterns your APIs are going to be more reusable and will provide a better foundation for others to build on.